In the last section, we saw how word embeddings can be used with the Keras sequential API. While the sequential API is a good starting point for beginners, as it allows you to quickly create deep learning models, it is extremely important to know how Keras Functional API works. Most of the advanced deep learning models involving multiple inputs and outputs use the Functional API.

Introduction The Keras functional API is a way to create models that are more flexible than the tf.keras.Sequential API. The functional API can handle models with non-linear topology, shared layers, and even multiple inputs or outputs. The main idea is that a deep learning model is usually a directed acyclic graph of layers.

The Keras functional API helps create models that are more flexible in comparison to models created using sequential API. The functional API can work with models that have non-linear topology, can share layers and work with multiple inputs and outputs. A deep learning model is usually a directed acyclic graph that contains multiple layers. The functional API helps build the graph of layers. Convolutional layers are the major building blocks used in convolutional neural networks. Learning to see and after training many different ways of seeing the input data.

Neural networks play an important role in machine learning. Inspired by how human brains work, these computational systems learn a relationship between complex and often non-linear inputs and outputs. A basic neural network consists of an input layer, a hidden layer and an output layer.

Each layer is made of a certain number of nodes or neurons. Neural networks with many layers are referred to as deep learning systems. We tried to predict how many reposts and likes a news headline on Twitter. The model will also perform supervised learning through two loss functions.

Using the main loss function in the model earlier is a good regular method for deep learning models. You should be now familiar with word embeddings, why they are useful, and also how to use pretrained word embeddings for your training. You have also learned how to work with neural networks and how to use hyperparameter optimization to squeeze more performance out of your model. Now you are ready to use the embedding matrix in training.
Let's go ahead and use the previous network with global max pooling and see if we can improve this model. When you use pretrained word embeddings you have the choice to either allow the embedding to be updated during training or only use the resulting embedding vectors as they are. The Keras functional API is a way to create models that are more flexible than the tf. Sequential API. The functional API can handle models with non-linear topology, shared layers, and even multiple inputs or outputs.

So the functional API is a way to build graphs of layers. Keras functional API allows us to build each layer granularly, with part or all of the inputs directly connected to the output layer and the ability to connect any layer to any other layers. Features like concatenating values, sharing layers, branching layers, and providing multiple inputs and outputs are the strongest reason to choose the functional api over sequential.

I had created keras deep learning model with glove word embedding on imdb movie set. I had used 50 dimension but during validation there is lot of gap between accuracy of training and validation data. I have done pre-processing very carefully using custom approach but still I am getting overfitting. The main function for using the Functional API is called keras_model(). With keras_model, you combine input and output layers.
To make it easier to understand, let's look at a simple example. Below, I'll be building the same model from last week's blogpost, where I trained an image classification model with keras_model_sequential. Just that now, I'll be using the Functional API instead. The script remains the same, except for the embedding layer.

Here in the embedding layer, the first parameter is the size of the vacabulary. The second parameter is the vector dimension of the output vector. Since we are using pretrained word embeddings that contain 100 dimensional vector, we set the vector dimension to 100. In the script above, we create a Sequential model and add the Embedding layer as the first layer to the model. The length of the vocabulary is specified by the vocab_length parameter. The dimension of each word vector will be 20 and the input_length will be the length of the longest sentence, which is 7.

Next, the Embedding layer is flattened so that it can be directly used with the densely connected layer. Since it is a binary classification problem, we use the sigmoid function as the loss function at the dense layer. We can create a simple Keras model by just adding an embedding layer. In the above example, we are setting 10 as the vocabulary size, as we will be encoding numbers 0 to 9.

We want the length of the word vector to be 4, hence output_dim is set to 4. The length of the input sequence to embedding layer will be 2. We don't have much control over input, output, or flow in a sequential model. Sequential models are incapable of sharing layers or branching of layers, and, also, can't have multiple inputs or outputs. If we want to work with multiple inputs and outputs, then we must use the Keras functional API.

In addition to these carefully designed methods, a word embedding can be learned as part of a deep learning model. This can be a slower approach, but tailors the model to a specific training dataset. This script loads pre-trained word embeddings into a frozen Keras Embedding layer, and uses it to train a text classification model on the 20 Newsgroup dataset . Model class Keras functional API is a method for defining complex models (such as multi-output models, directed acyclic graphs, or models with shared layers) Fully connected network T...

Both the headline, which is a sequence of words, and an auxiliary input will be given to the model that accepts data, for example, at what time or the date the headline got posted, etc. To use text data as input to the deep learning model, we need to convert text to numbers. However unlike machine learning models, passing sparse vector of huge sizes can greately affect deep learning models. Therefore, we need to convert our text to small dense vectors. Word embeddings help us convert text to dense vectors. Firstly thank you so much for the great webpage you have.

It has been a great help from the first day I started to work on deep learning. What is the corresponding loss function for the model with multiple inputs and one output that you have in subsection Multiple Input Model? I want to know if you have X1 and X2 as inputs and Y as outputs, what would be the mathematical expression for the loss function. The Keras functional API is a way to create models that are more flexible than the tf.keras.Sequential API.

One way is to train your word embeddings during the training of your neural network. The other way is by using pretrained word embeddings which you can directly use in your model. There you have the option to either leave these word embeddings unchanged during training or you train them also.

In this tutorial, you'll see how to deal with representing words as vectors which is the common way to use text in neural networks. Two possible ways to represent a word as a vector are one-hot encoding and word embeddings. This also cannot be handled with the Sequential API .
Examples include an Auxiliary Classifier Generative Adversarial Network and neural style transfer. In this article we saw how word embeddings can be implemented with Keras deep learning library. We implemented the custom word embeddings as well as used pretrained word embedddings to solve simple classification task. Finally, we also saw how to implement word embeddings with Keras Functional API.

To get the number of unique words in the text, you can simply count the length of word_index dictionary of the word_tokenizer object. This is to store the dimensions for the words for which no pretrained word embeddings exist. You can see that the first layer has 1000 trainable parameters.

This is because our vocabulary size is 50 and each word will be presented as a 20 dimensional vector. Hence the total number of trainable parameters will be 1000. Similarly, the output from the embedding layer will be a sentence with 7 words where each word is represented by a 20 dimensional vector.

However, when the 2D output is flattened, we get a 140 dimensional vector . The flattened vector is directly connected to the dense layer that contains 1 neuran. You can add more layers and more neurons for predicting the 2nd output. This is where the functional API wins over the sequential API, because of the flexibility it offers. Using this we can predict multiple outputs at the same time.

We would have built 2 different neural networks to predict outputs y1 and y2 using sequential API but the functional API enabled us to predict two outputs in a single network. Real-life problems are not sequential or homogenous in form. You will likely have to incorporate multiple inputs and outputs into your deep learning model in practice. How to define more complex models with shared layers and multiple inputs and outputs. Keras Functional API is used to delineate complex models, for example, multi-output models, directed acyclic models, or graphs with shared layers.

In other words, it can be said that the functional API lets you outline those inputs or outputs that are sharing layers. This method represents words as dense word vectors which are trained unlike the one-hot encoding which are hardcoded. This means that the word embeddings collect more information into fewer dimensions.

In this article we cover the two word embeddings in NLP Word2vec and GloVe. And popular Natural Language Processing NLP using Python course! Most realworld problems contain a dataset that has a large volume of rare words. It's a feedforward neural network with just one hidden layer. Another common use-case for the Functional API is building models with multiple inputs or multiple outputs. Here, I'll show an example with one input and multiple outputs.

Note, the example below is definitely fabricated, but I just want to demonstrate how to build a simple and small model. Most real-world examples are much bigger in terms of data and computing resources needed. You can find some nice examples here and here (albeit in Python, but you'll find that the Keras code and function names look almost the same as in R).

In Keras, we create neural networks either using function API or sequential API. In both the APIs, it is very difficult to prepare data for the input layer to model, especially for RNN and LSTM models. This is because of the varying length of the input sequence. There are a few different embedding vector sizes, including 50, 100, 200 and 300 dimensions. You can download this collection of embeddings and we can seed the Keras Embedding layer with weights from the pre-trained embedding for the words in your training dataset.
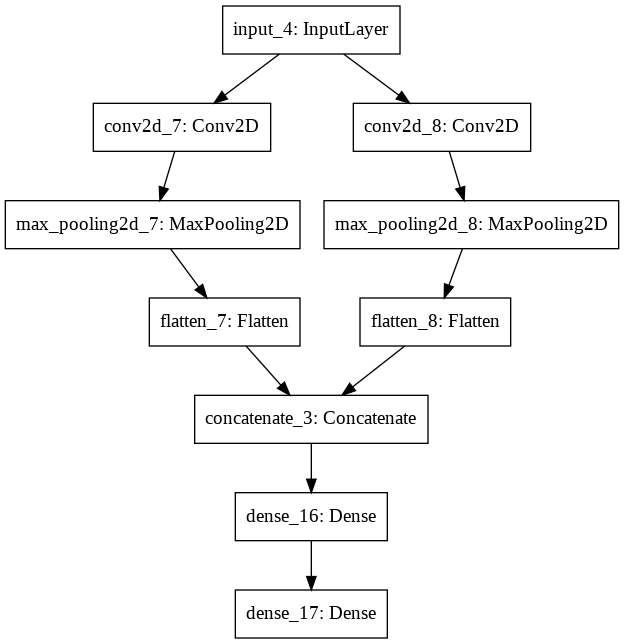
The model takes black and white images with the size 64×64 pixels. There are two CNN feature extraction submodels that share this input; the first has a kernel size of 4 and the second a kernel size of 8. In the functional API, models are created by specifying their inputs and outputs in a graph of layers. That means that a single graph of layers can be used to generate multiple models.

In this section, we'll look at how to fit neural networks on text classification problems while learning about word embedding. The embedding layer is initialized with random weights and all words in the learning training data set are embedded. Start using Keras functional API The Keras functional API is a way to define complex models (such as multi-output models, directed acyclic graphs, or models with shared layers). I also find a very interesting similarity between word embedding to the Principal Component Analysis. Although the name might look complicated the concept is straightforward. What PCA does is to define a set of data based on some general rules (so-called principle components).
So it's like having a data and you want to describe it but using only 2 components. Which in this sense is very similar to word embeddings. They both do the same-alike job in different context. I hope maybe understanding PCA helps understanding embedding layers through analogy.



